深度解析AI在社交平台生态、剧本杀及TRPG领域的市场格局与发展趋势
腾讯AI战略的核心在于打通元宝生态,将AI系统性融入游戏、广告及企业服务。微信作为最大的抓手,未来将推出能理解用户意图并调用小程序、支付等能力的AI智能体[272]。
通信社交
理解用户需求与意图
内容生态
公众号与视频号
小程序生态
覆盖绝大部分互联网用例
商业与支付
即时完成购买与支付
74.73%
消费者玩过剧本杀
69.76%
偏好开放本
华创证券预测未来可达千亿市场规模,对标KTV等线下娱乐方式[254]。

沉浸式线下体验
满足年轻人多元社交与情感需求
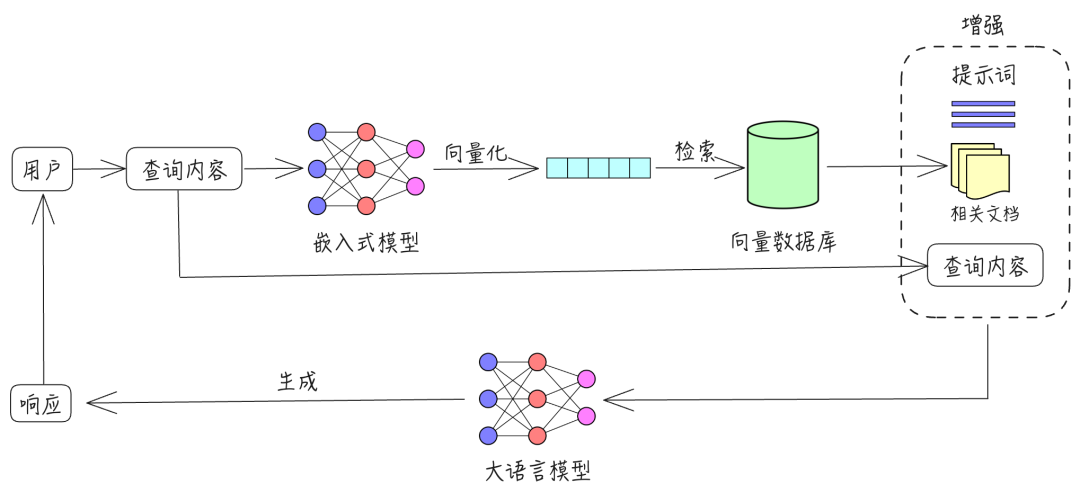
结合大模型与检索增强生成,作为个人跑团助手。
尽管行业面临剧本质量不均、同质化严重等挑战,但这恰恰为AI技术提供了广阔空间。支付环境的改善(如苹果与微信协议达成)将进一步释放AI小程序的商业潜力[276]。AI将推动行业向更高质量、更个性化方向发展。
深入剖析用户在组织游戏、DM资源短缺等方面的核心痛点
剧本杀作为4-10人的团队游戏,在实际组织过程中面临巨大挑战。
基于行业调研的核心痛点占比分析

智能主持、NPC互动、剧本生成、辅助工具
体验需求
技术需求

人类DM负责情感表达、创意创作、临场反应,AI负责规则计算、信息管理、重复性任务[424]【425】。
第一阶段(1-2年):辅助工具
规则查询、线索管理,建立AI与人类DM协作模式。
第二阶段(3-5年):部分自动化
实现部分游戏流程自动化,提高AI自主性。
第三阶段(5年以上):高度智能化
高度智能化主持,个性化定制,探索全新游戏模式。
解析适用于互动娱乐的前沿AI技术,深入探讨Agent智能体架构与RAG检索增强生成在剧本杀与跑团场景中的落地应用
提供语言理解、逻辑推理和内容生成能力。在剧本杀中负责解析输入、生成对话、描述场景和处理规则。
存储历史交互,维护连贯性。分层架构包含短期记忆(即时信息)、长期记忆(角色设定)和知识库(规则背景)[166]。
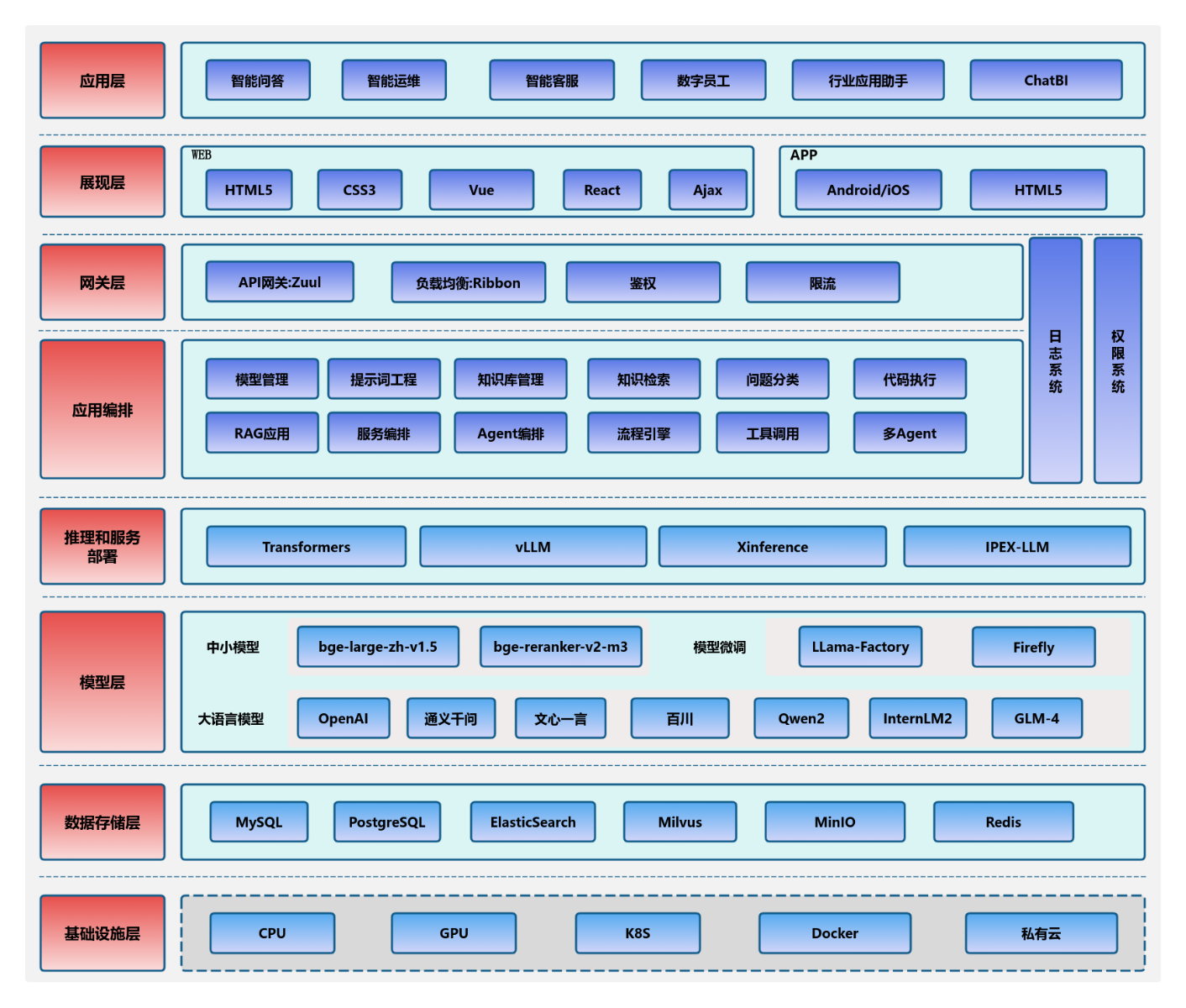
AI Agent智能体系统架构分层图
处理规则解释、骰子投掷、数值计算及背景信息提供。
深度解析AI在NPC智能扮演、动态剧本生成、规则自动判定等核心场景中的应用,结合DND与克苏鲁跑团实战案例
AI技术在社交平台及小程序的互动娱乐领域展现出强大的应用潜力,特别是在NPC智能扮演、动态剧本生成和规则自动判定等核心场景中,正在重塑用户的娱乐体验。以下将详细阐述这些应用模式,并结合DND(龙与地下城)和克苏鲁跑团的具体案例展示实际效果。
AI NPC已从简单的对话机器人发展为具有深度个性、情感理解和持续记忆的智能虚拟角色。通过自然语言处理和大语言模型,NPC能够"理解"用户意图和情感基调,甚至"记住"玩家过去的选择,打破传统NPC僵化的对话模式[556]。
利用生成式AI技术实时创建游戏内容,包括故事情节、对话、任务和事件,为每个玩家提供独特的、个性化的游戏体验。
多系统协同架构,包含玩家助手、新兴叙事、游戏状态管理等五大系统。
Rosebud AI RPG Maker
从描述到代码,浏览器端即时分享
Convai 智能角色
结合NVIDIA ACE,支持Unity/Unreal集成
AI正在以前所未有的方式重塑社交互动娱乐体验,推动行业进入全新的沉浸式时代。
评估在社交平台与小程序环境中部署AI应用的具体实施路径,解析性能优化与工程化挑战
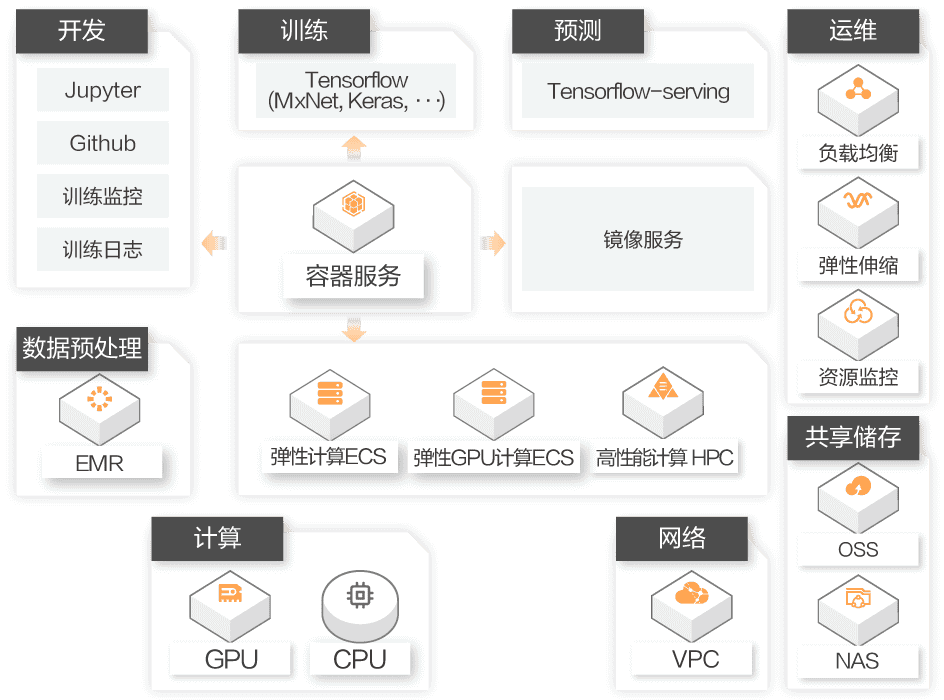
云原生AI部署架构:从开发、训练到预测的完整技术栈
技术选型:NapCat + OneBot v11
技术选型:Wechaty SDK + Puppet
技术选型:微信云开发 (CloudBase)
| 类型 | 过期时间 | 性能提升 |
|---|---|---|
| 会话缓存 | 60s | 减少查询80% |
| 向量缓存 | 3600s | 减少调用70% |
| 特性缓存 | 600s | 减少查询90% |
多队列隔离(Dataset/Plugin/Monitor),支持任务优先级与重试,提升吞吐量300%+。
量化技术降低显存占用75%,配合KV Cache复用,加速多轮对话推理。
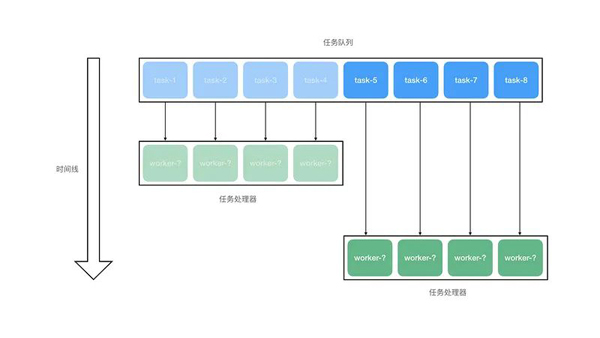
异步任务队列:任务入队、分配与并行处理逻辑
@app.route('/api/process')
def process_data():
data = request.get_json()
# 异步提交后台任务
process_task.delay(data)
return {'status': 'processing'}结合RAG检索增强与向量索引(FAISS),通过动态阈值筛选相关历史,解决长程依赖与Token限制问题。
基于ViT编码器与多模态大模型(如GPT-4V),实现图像特征提取与图文联合问答。
def analyze_image(image, question):
base64_img = encode_image(image)
messages = [{
"role": "user",
"content": [
{"type": "text", "text": question},
{"type": "image_url",
"image_url": {"url": base64_img}}
]
}]
return openai.ChatCompletion.create(
model="gpt-4-vision",
messages=messages
)
挑战
LLM API调用不稳定、连接池耗尽、任务堆积。
方案
引入Redis多级缓存,Celery异步队列,配置水平扩展增加Worker。
挑战
Token序列限制(8k),长程依赖丢失,一致性难保持。
方案
采用分层记忆系统,语义压缩技术,RAG检索外部知识库辅助。
挑战
QQ/微信非官方接入易封号,算法备案要求严格。
方案
使用专用小号,实施频率限制,配置内容过滤,定期进行安全审计。
响应延迟 (P90)
< 2s
并发吞吐量
100+ QPS
GPU利用率
> 70%
错误率 (5xx)
< 1%
客观评估当前AI技术的局限性与安全风险,构建合规的应用防线
幻觉(Hallucination)是大型语言模型最根本的局限性之一,指模型生成看似合理但与事实不符、无意义或完全虚构的信息的现象。这一特性已被严格的数学理论证明是LLM的必然特性。
理论必然性
2024年1月的arxiv论文《Hallucination is Inevitable》从数学角度证明了幻觉是LLM的必然特性。研究证明LLM无法学习所有可计算函数,因此总会产生幻觉[198]。2025年6月的论文进一步证明了创建不产生幻觉的大语言模型的不可能性[207]。
幻觉分类
量化影响

差分隐私
训练数据添加可控噪声,ε=0.5设置下隐私重构成功率从85%降至10%以下。
联邦学习
数据分布式存储,仅上传模型参数,避免原始数据集中传输。
合成数据生成
利用GAN创建不含个人信息的人工数据集,从根本上规避风险。
中国监管框架
监管要求
Agent产品合规[384]
数据获取合规